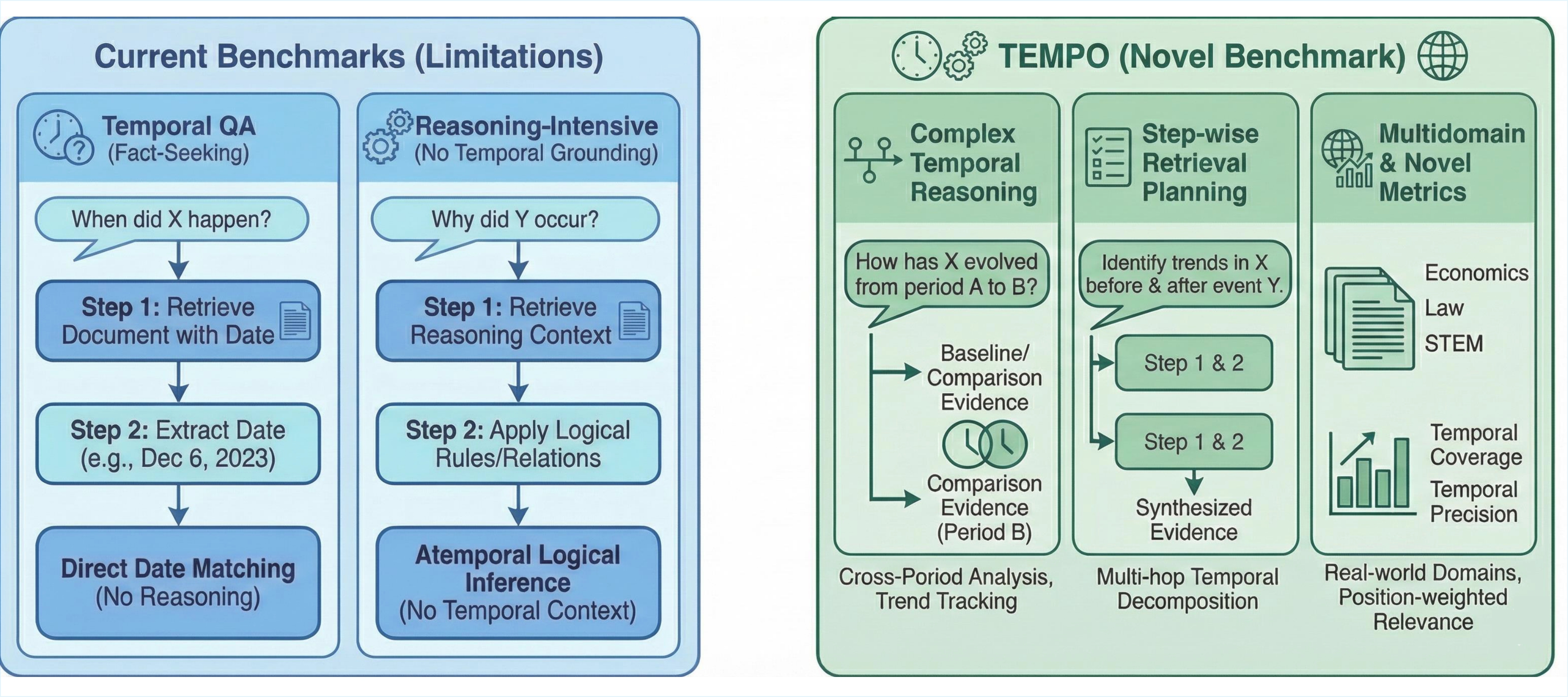
Why a new benchmark?
Existing temporal QA benchmarks focus on fact-seeking queries from news corpora, while reasoning-intensive retrieval benchmarks lack temporal grounding. Real-world information needs often require reasoning about temporal evolution and synthesizing evidence across time periods. We introduce TEMPO to better benchmark retrieval on such challenging and realistic scenarios.
TEMPO
TEMPO is the first benchmark combining temporal reasoning with reasoning-intensive retrieval across 13 domains. It features 1,730 complex queries, 3,976 step-wise retrieval plans mapped to gold documents, and novel temporal metrics including Temporal Coverage@k and Temporal Precision@k.
Leaderboard submission
If you would like to submit your results to the leaderboard, please open a pull request or issue on our GitHub repository.
Have Questions?
Contact the authors or open an issue on GitHub.
Leaderboard
Simplified leaderboard showing Average NDCG@10, Temporal Precision (TP), and Temporal Coverage (TC).
| Rank | Model | Type | Avg NDCG@10 | TP@10 | TC@10 |
|---|---|---|---|---|---|
| 🥇 1 | DiVeR | Reasoning | 32.0 | 62.0 | 71.4 |
| 🥈 2 | E5 | Dense >1B | 30.4 | 53.5 | 63.2 |
| 🥉 3 | SFR | Dense >1B | 30.0 | - | - |
| 4 | GritLM | Dense >1B | 27.2 | 53.8 | 69.1 |
| 5 | ReasonIR | Reasoning | 27.2 | 57.4 | 72.4 |
| 6 | SBERT | Dense <1B | 24.9 | 54.1 | 67.2 |
| 7 | Inst-L | Dense <1B | 24.8 | 53.1 | 66.9 |
| 8 | Rader | Reasoning | 24.2 | 50.6 | 66.1 |
| 9 | Qwen | Dense >1B | 22.8 | 46.2 | 61.0 |
| 10 | BGE | Dense <1B | 22.0 | 53.7 | 66.1 |
| 11 | Contriever | Dense <1B | 21.4 | 49.6 | 64.1 |
| 12 | BM25 | Sparse | 10.8 | 24.0 | 32.8 |